
Refactoring a Legacy Codebase with Claude Code
How I used Claude Code and the grill-me skill to finally plan a proper cleanup of my website codebase.

Let’s dive into the world of LLMs and explore how tools like LangChain make it easy to create more dynamic applications.
Ruben Dewitte - 14 min read
AI is all the rage these days, especially with the widespread adoption of tools like ChatGPT. But what’s really happening behind the scenes with apps like that?
This article aims to lift the curtain on LLMs. Whether you’re just curious about how they shape tools like ChatGPT or eager to start building your own AI-driven applications, you’re in the right place. Here’s what we’ll dive into:
By the end, you’ll have a clearer picture of how LLMs operate, how to choose the right model for your task, and how to leverage tools and frameworks that simplify your development process.
In a nutshell a Large Language Model (LLM) is essentially a sophisticated text generator. It creates text by predicting the next sequence of words based on the input (prompt) it receives. Its output is determined by the patterns and relationships it learned from the datasets used during training.
For the sake of scope, we will focus exclusively on LLMs, which specialize in NLP (Natural Language Processing). Within AI, other domains like Computer Vision and Audio exist, but these fall outside the scope of this discussion.
Selecting the right model is one of the most critical decisions. Each LLM offers unique advantages and trade-offs. Here are some of the most popular vendors and their general-purpose models:
Many publicly available LLM APIs charge based on token usage, where tokens are chunks of text such as words, parts of words, or even individual characters. For example, the phrase "Hello, world!" can be broken down into tokens like "Hello,", ",", and "world!".
OpenAI’s GPT-4 costs $2.50 per 1 million tokens. These costs can quickly add up when processing large datasets, or analyzing lengthy documents, since each interaction with the AI model 'consumes' tokens.
For example, if you're building an AI-powered PR reviewer bot that processes multiple files of code with each new request, the tokens that are inputted into the LLM (entire codebase or diffs) can add up rapidly.
The LLMs above are general-purpose models and pretty good at a lot of things. But for certain tasks, it might make sense to use a model that's specialized for that job. For example, Salesforce's CodeGen is a text-generation model that's trained specifically to be great at generating code.
While pre-trained models such as the ones mentioned above are often sufficient, fine-tuning allows developers to adapt these models for specific tasks, think of things like summarizing legal documents or analyzing scientific literature.
Fine-tuning combines the advantages of pre-trained general-purpose models with custom capabilities, and it is far more resource-efficient than training a model from scratch.
There are 2 types of training architectures that are employed to train a language model. Each model training method having advantages for specific use cases.
An MLM can predict a token (e.g., a word) that is masked (e.g., missing) in a sequence (e.g., a sentence). To do so, an MLM has access to tokens bidirectionally, meaning it is aware of the tokens on both the left and right sides of the sequence. MLMs excel at tasks requiring strong contextual understanding, such as text classification, sentiment analysis, and named entity recognition. While they are proficient at understanding text, they are not well-suited for generating new text.
In short: MLMs optimize for understanding (contextualizing data without necessarily generating new content).
A CLM can predict a token (e.g., a word) in a sequence of tokens. To achieve this, the model can only access tokens on the left side of the token being predicted, meaning it lacks knowledge of future tokens. A good example of a CLM in practice is an intelligent coding assistant, such as Copilot.
Before the introduction of BERT (Bidirectional Encoder Representations from Transformers) in 2018, CLMs were the gold standard for language modeling. While CLMs remain essential for generative tasks, MLMs are increasingly used for tasks requiring in-depth text understanding.
In short: CLMs optimize for generation (producing coherent outputs from given inputs).
For many individuals and companies, sending their data to a remote LLM hosted elsewhere can pose privacy and security concerns, especially for sensitive organizations like banks.
Fortunately, numerous open-source and publicly available models can be run directly on personal machines or virtual private servers.
Some popular open-source LLM models are Llama from Meta and Qwen from Alibaba Cloud
Hugging Face is a platform where people can share various types of (open-source) AI models, datasets as well as fine-tuned models based on existing ones. It is the largest hub for sharing AI models and related resources.
Major players in the industry, such as OpenAI, have also uploaded some of their older GPT models to Hugging Face under the MIT license. Hugging Face is free to use unless you want to use their cloud to host your AI model.
While not all models are open source and each typically comes with its own license, they are all available for download and can be used on your own machine.
Hugging Face also provides its own (as well as community-maintained) transformers package in Python, enabling you to download various models—from object detection to text generation—directly into your application.
In essence, developing applications using LLMs involves providing a pre-trained model with a prompt in its required format, receiving the result, and then parsing the text output for use in a user-facing application.
An LLM on its own is limited to text generation based on the input it receives. Features loading data from websites, memory, and other advanced features such as those found in tools like ChatGPT—are not inherent to the LLM itself but must be built on top of it.
Managing these tasks manually can be cumbersome, especially since each LLM application may have its own specific requirements. Fortunately, LangChain simplifies this process.
LangChain provides tools and abstractions that allow developers to focus on the application's needs rather than dealing with API peculiarities, boilerplate code, or reinventing the wheel.
LangChain is available in Python and JavaScript. Python is more popular and has better support from other libraries like Hugging Face. For example, the Hugging Face pipeline library isn’t available in JavaScript, so you’re stuck using their Inference API, which means interacting with a model hosted remotely instead of running it on your own machine.
Overall, JavaScript seems like the better option if all you need is to interface with a model that is running in the cloud.
LangChain can be used in two primary ways: either by interfacing directly with a local model or through an API provided by major vendors. LangChain offers abstractions for all the major vendors.
Running a model locally with LangChain and invoking it is straightforward. By using the HuggingFace Python API, we can easily download and invoke a local LLM as shown below:
from langchain_huggingface import HuggingFacePipeline llm = HuggingFacePipeline.from_model_id( model_id="microsoft/Phi-3-mini-4k-instruct", task="text-generation", pipeline_kwargs={ "max_new_tokens": 100, # Limits the number of tokens generated in response to input "top_k": 50, # Reduces vocabulary size "temperature": 0.1, # Controls randomness: higher values increase diversity }, ) llm.invoke("Hugging Face is")
LangChain also provides wrappers for the Hugging Face API, enabling you to run prompts on a dedicated endpoint hosted by Hugging Face. This can be done using the HuggingFaceEndpoint class.
Large LLMs need a lot of computing power to run, which makes them expensive to host. Because of this, most models aren't free to use. To interact with a remote model, you'll first need to create an account with the vendor offering the model and retrieve the API keys necessary for accessing it. LangChain simplifies this process by allowing you to easily configure and apply your API keys for specific vendors.
Keep in mind that costs can rack up quickly!
To get started with LangChain and interface with a remote model like OpenAI, follow these steps:
Install the LangChain OpenAI package:
npm install @langchain/openai
Add Environment Variables:
Add the following to your .env file:
OPENAI_API_KEY=your-api-key
Instantiate the Model: After setting up the environment variable, you can instantiate the model within your application:
import { ChatOpenAI } from "@langchain/openai"; const model = new ChatOpenAI({ model: "gpt-4" });
It's very important to note that every model has it's own 'syntax' for prompting to the model. LLM models are VERY sensitive to you providing the correct prompt format. If you don't, the model will perform significantly worse.
In a nutshell language models operate with three distinct roles for prompts:
Prompt formats distinguish these roles, helping the System identify who is communicating. The initial message in any sequence is the System prompt, which sets the model's behavior. After that, interactions are with the Assistant role created by the System prompt.
Using LangChain's JavaScript API, you can easily prompt any major vendor's model with the following example:
import { ChatOpenAI } from "@langchain/openai"; import { HumanMessage, SystemMessage } from "@langchain/core/messages"; const model = new ChatOpenAI({ model: "gpt-4" }); const messages = [ new SystemMessage("Translate the following from English into Italian"), new HumanMessage("hi!"), ]; await model.invoke(messages);
LangChain provides abstractions for virtually all major vendors. Here are some example classes: ChatOpenAI, ChatAnthropic, ChatFireworks, ChatMistralAI, ChatGroq, and ChatVertexAI.
When developing applications with LLMs, one limitation to keep in mind is the size of the context window. This context window determines how much text (in tokens) the model can handle in a single interaction. Larger models can handle bigger context windows, but they can still struggle with tasks needing a lot of data at once.
For example, if your application needs to analyze an entire codebase, the context window might not be large enough to fit all the files simultaneously. This can become a challenge when the task requires the model to access a wide range of information across multiple documents.
A practical solution is to supply the model with only the most relevant information it needs to answer the given question or problem. This approach is also known as RAG (Retrieval-Augmented Generation).
Now lets we'll dive deeper into what RAG entails and how we can use RAG in combination with LangChain!
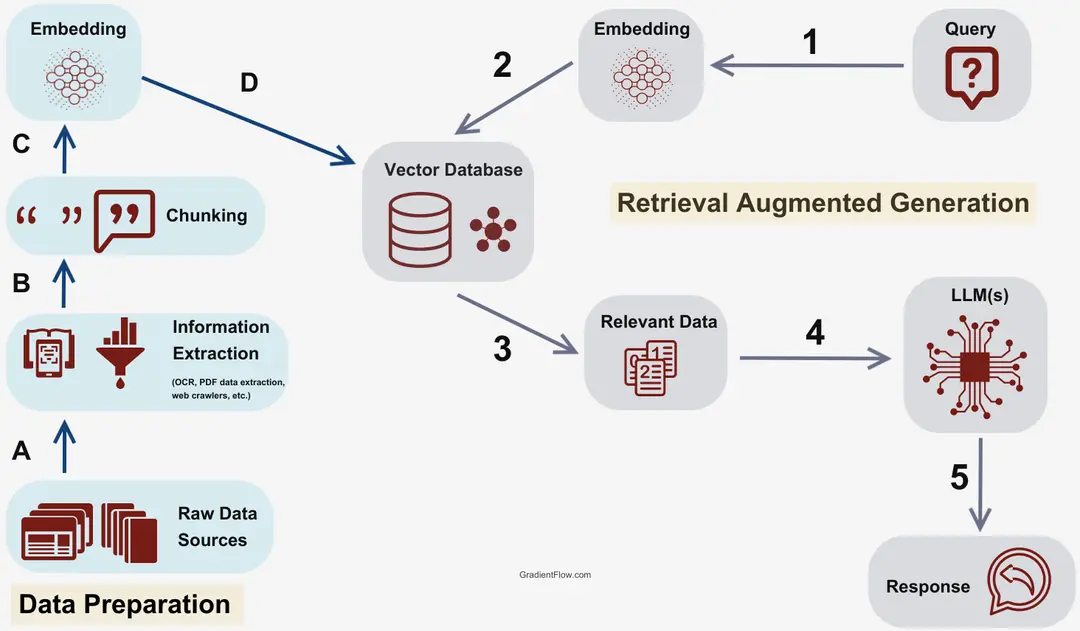 Source: Gradient Flow
Source: Gradient Flow
Loading the data
First, we need to load the data we require. In LangChain, this can be done using document loaders. There are many kinds of document loaders, such as CSV loaders, Markdown loaders, and more. The one we will use for this example is a website loader.
import "cheerio"; import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio"; const loader = new CheerioWebBaseLoader( "https://lilianweng.github.io/posts/2023-06-23-agent/" ); const docs = await loader.load();
Splitting the data
After we've loaded the required data, we will split it into chunks. This is because they are easier to search over, and larger documents won't fit in the context window. For this, we will use the RecursiveCharacterTextSplitter class provided by LangChain.
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter"; const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 200, }); const splits = await textSplitter.splitDocuments(docs);
This will split the data in equal chunks of the provided size, with also providing some overlap between chunks, so that no context is lost that might be stored in the previous or next chunk.
Storing/embedding the data
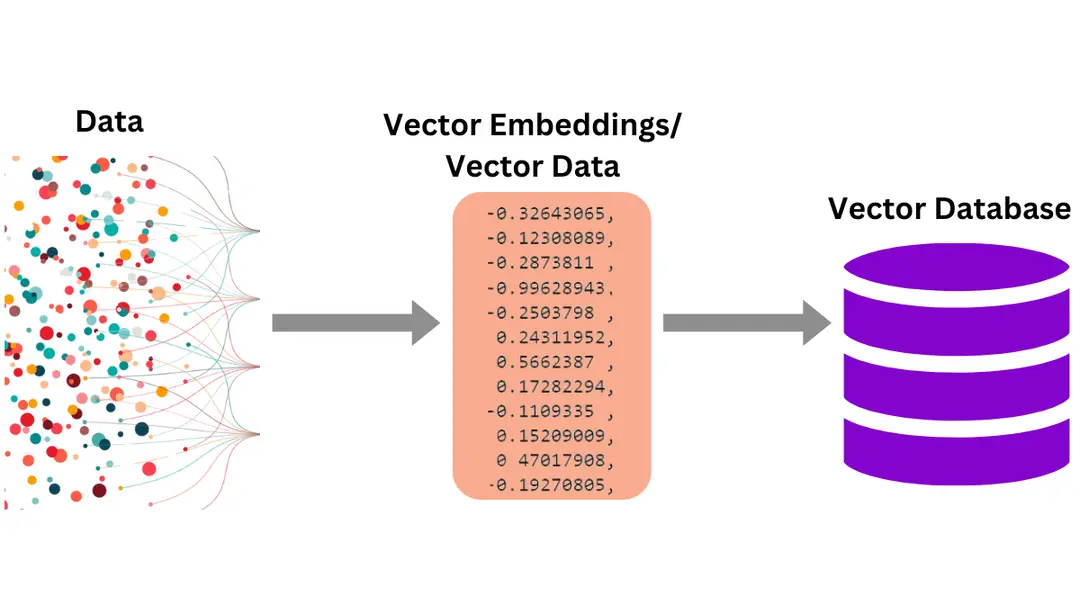 Source: Storing Vector Embeddings
Source: Storing Vector Embeddings
After we split our data into smaller pieces, we need a way to store it so that we can easily find relevant information later. One effective strategy is to transform the text into a form that computers can easily compare and understand.
This is where an embeddings model comes into play. It takes words or entire documents and represents them as a list of numbers like [-0.1, 0.5, 0.8]. These lists of numbers, called vectors, capture the meaning and relationships between words, acting like coordinates that map out how different pieces of information relate to each other.
Once we have these vectors, we place them into a special database known as a vector store. Vector stores are designed to efficiently organize and search through a large collections of vectors.
In the following example, we'll use a MemoryVectorStore, which will store embeddings created by the OpenAI embedder OpenAIEmbeddings directly in our application's memory.
import { OpenAIEmbeddings } from "@langchain/openai"; import { MemoryVectorStore } from "langchain/vectorstores/memory"; // Using OpenAI's pre-trained model for creating embeddings const vectorStore = await MemoryVectorStore.fromDocuments( splits, new OpenAIEmbeddings() );
When we want to find information that’s similar to a new prompt or question, we run that prompt through the same embeddings model to produce another vector. We then measure how “close” this new vector (this is done under the hood using simple distance calculations) is to the ones stored in the database. The closer the vectors, the more similar or relevant the information is.
That way, we can easily find the chunk of context that matches the prompt that was given.
// We can then run a similarity search using the prompt that was provided const docs = vectorStore.similaritySearch("What is Task Decomposition?")
LangChain using LCEL
After preparing our vector store with embedded documents, we can create a complete RAG pipeline using LangChain Expression Language (LCEL). LCEL provides a simple, intuitive way to chain together different components of our retrieval and generation workflow.
LangChain provides pre-made prompts available through their community hub, one of which is specifically designed for RAG queries. Here’s an example of the prompt used for such queries:
human You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. Question: {question} Context: {context} Answer:
In the above prompt, the question and context will be passed into the LCEL chain, and the model will return a response. The result will be returned as an AIMessage from LangChain, which we’ll need to parse into a string using the StringOutputParser.
import { StringOutputParser } from "@langchain/core/output_parsers"; import { RunnablePassthrough, RunnableSequence, } from "@langchain/core/runnables"; import { formatDocumentsAsString } from "langchain/util/document"; import { ChatPromptTemplate } from "@langchain/core/prompts"; import { pull } from "langchain/hub"; import { ChatOpenAI } from "@langchain/openai"; const llm = new ChatOpenAI({ model: "gpt-4o-mini", temperature: 0 }); const vectorStoreRetriever = vectorStore.asRetriever({ searchType: "similarity", }); const ragPrompt = await pull<ChatPromptTemplate>("rlm/rag-prompt"); const runnableRagChain = RunnableSequence.from([ { context: vectorStoreRetriever.pipe(formatDocumentsAsString), question: new RunnablePassthrough(), }, ragPrompt, llm, new StringOutputParser(), ]); await runnableRagChain.invoke({ question: "What is Task Decomposition?", context, });
The above defined chain does the following in sequence:
RunnablePassthrough() is a component from LangChain that essentially does exactly what its name suggests, it "passes through" the input without changing it. In this case, it makes sure that the original question is preserved and passed forward without modification.
Agents rely on a language model to figure out what actions to take and in what order. In chains, the actions and their order are fixed in the code. With agents, the language model decides the actions step by step as it goes.
We can combine agents with LangGraph, a framework in the LangChain ecosystem, to build smart and flexible workflows. LangGraph adds structure to this by acting like a map. It defines the steps and paths available, helping agents navigate workflows efficiently. Think of LangGraph as the guide that says, “Here are your options,” while the agent decides, “This is the best path.”
Agents can also use tools to help them. A tool is something the agent can use when needed, like calling a web API, doing a calculation, or searching for information.
Here’s how an agent works:
Below is an implementation example where a LangGraph is paired with a tool that will retrieve data from the vector store if needed. If no retrieval is needed, the agent responds directly.
import { AIMessage, BaseMessage, HumanMessage } from "@langchain/core/messages"; import { tool } from "@langchain/core/tools"; import { ChatOpenAI } from "@langchain/anthropic"; import { StateGraph } from "@langchain/langgraph"; import { MemorySaver, Annotation, messagesStateReducer } from "@langchain/langgraph"; import { ToolNode } from "@langchain/langgraph/prebuilt"; const StateAnnotation = Annotation.Root({ messages: Annotation<BaseMessage[]>({ // Reducer function for managing the `messages` state // It appends new messages to the list and updates existing messages by their ID reducer: messagesStateReducer, }), }); // Define a simple weather tool for querying weather information // This weather tool is just a dummy implementation of an actual weather tool. // In a real world example you would query an online Weather API const weatherTool = tool(async ({ query }) => { const queryLowerCase = query.toLowerCase(); if (queryLowerCase.includes("sf") || queryLowerCase.includes("san francisco")) { return "It's 60 degrees and foggy in San Francisco."; } return "It's 90 degrees and sunny."; }, { name: "weather", description: "Fetches current weather for a location.", }); // A good description is important so that the model knows when to use the tool or not // Array of tools for the agent to use const tools = [weatherTool]; const toolNode = new ToolNode(tools); const model = new ChatOpenAI({ model: "gpt-4" }); // Bind the tools to the model so it can invoke them as needed model.bindTools(tools); // Function to decide whether to continue the workflow or stop function shouldContinue(state: typeof StateAnnotation.State) { const messages = state.messages; const lastMessage = messages[messages.length - 1] as AIMessage; // If the LLM calls a tool, route to the "tools" node, otherwise stop return lastMessage.tool_calls?.length ? "tools" : "__end__"; } // Function to invoke the model and get a response async function callModel(state: typeof StateAnnotation.State) { const messages = state.messages; const response = await model.invoke(messages); return { messages: [response] }; } // Define the state graph with nodes and edges const workflow = new StateGraph(StateAnnotation) .addNode("agent", callModel) // Node for the agent's response .addNode("tools", toolNode) // Node for invoking tools .addEdge("__start__", "agent") // Start from the agent node .addConditionalEdges("agent", shouldContinue) // Conditional routing from agent node .addEdge("tools", "agent"); // After tool invocation, return to agent node // Initialize memory to persist state between graph runs const checkpointer = new MemorySaver(); // Compile the graph into a LangChain Runnable const app = workflow.compile({ checkpointer }); // Use the Runnable to invoke the workflow with a human message await app.invoke({ messages: [new HumanMessage("What is the weather in SF?")] });
It's important to note that tools will depend entirely on the LLM. If an LLM is weaker, it may not use the appropriate tools or may hallucinate the use of tools, either not using the correct tool at the right time or using it incorrectly. This can occur when the LLM misinterprets the problem or doesn’t have enough context to know when to invoke the tools.
If understood the general gist of this article, then you're basically ready to start building LLM-powered apps! With the basics in hand and tools like LangChain to do the heavy lifting, you can jump straight into the fun part: creating something awesome.

How I used Claude Code and the grill-me skill to finally plan a proper cleanup of my website codebase.

A language of life

A guide to copying JS arrays & objects; safely

A brief, practical tour of the new Signal Forms in Angular—setup, validation, template binding, and submission.

Signal-driven, reactive, and zoneless

Paving the way to exciting features

This is how I got into conference speaking as a software engineer, and how you can too.

Developer happiness, aiming for the next level!

Let’s dive into why web accessibility matters with tips to ensure your site works for everyone.
Expanding Your skillset for the Modern Job Market

Get ready to get the nitty gritty of our lovely framework

The eternal debate: Angular vs. React. It's like pineapple on a pizza, a discussion that never ends.
The secrets of Angular, new computed signals versus old getters

A look at some of the new exciting features in TypeScript 5.5

The new reactivity system for at least the next 10 years of Angular.

The team building and learning experience of the FrontValue Hackathon 2024.

Let's take a look at the improvements and new parts of React 19
How to share components across different frameworks from a single code base? How to implement Lit (web components) to React & Angular?

Running multiple applications together with Nx Monorepo.